Customize Pre-packaged Server
當現有提供的 Pre-packaged server 滿足不了實際需求時:
- 採用 PrimeHub 尚未支援的新machine learning library。
- 想要支援 serialization format 模型檔, 但 PrimeHub 尚未支援。
- 想要客製 monitoring metrics data
- 想要加入 preprocessing or postprocessing code
此文件以 Python model server 為例,並針對 PrimeHub Deployment model_uri 機制多加描述,另外可以參考 git repository primehub-seldon-servers.
我們將採用 skeleton server 裡的程式來解釋觀念。
pre-packaged server 如何運作?
查看此 skeleton server 的 Dockerfile:
FROM python:3.7-slim
COPY ./server /app
WORKDIR /app
RUN pip install -r requirements.txt
EXPOSE 5000
EXPOSE 9000
# Define environment variable
ENV MODEL_NAME Model
ENV SERVICE_TYPE MODEL
ENV PERSISTENCE 0
CMD exec seldon-core-microservice $MODEL_NAME --service-type $SERVICE_TYPE --persistence $PERSISTENCE --access-log
可以注意到 entrypoint 為 seldon-core-microservice 帶有參數 $MODEL_NAME (Model)。seldon-core-microservice 扮演 HTTP server 接收來自客戶端的請求,並轉達請求至模型; seldon-core-microservice 會先行驗證並轉換資料至對應的格式給 Model, Model 接著呼叫 predict 並傳回結果。
所以客製 pre-packaged server 的主要目標是客製 Model 裡 python module 這一塊。
Model module
此範例,我們定義 MODEL_NAME 為 Model,也就是說 Model.py 檔有定義 Model class。seldon-core-microservice 需要載入 Python module Model 並取得 class Model:
- 載入 python module Model.py
- 檢查是否 class 名 Model 定義於載入 module
- 建立 Model object
概念上 pseudo code 看起來會像:
# create a user_model and delegate client calls to it
user_model = Model(**parameters)
# load model if load method implemented
user_model.load()
# response the result of the predict method
user_model.predict(features, feature_names, **kwargs)
此為 Python model class 的簡易範本, 我們必須要實作 predict 來回傳運算結果:
class Model:
def __init__(self, model_uri=None):
# initialization
# 1. configure model path from the model_uri if needed
self.model_uri = model_uri
self.model = None
# 2. initialize the predictor
# you might want to enable GPU if it is not enabled automatically
# 3. invoke load method to preload the model
self.ready = False
self.load()
def load(self):
# load and create a model
# if model_uri was given, load data and create model instance from it
if self.ready:
return
# build model
# 1. set to self.model
# 2. make set.ready = True
self.ready = True
def predict(self, X, feature_names = None, meta = None):
# execute self.model.predict(X)
print(X, feature_names, meta)
return "Hello Model"
Handle model files
在 PrimeHub Deployment 我們可以透過 Model URI 來指定模型檔載入的位置:
PrimeHub users could create a Deployment with Model URI:
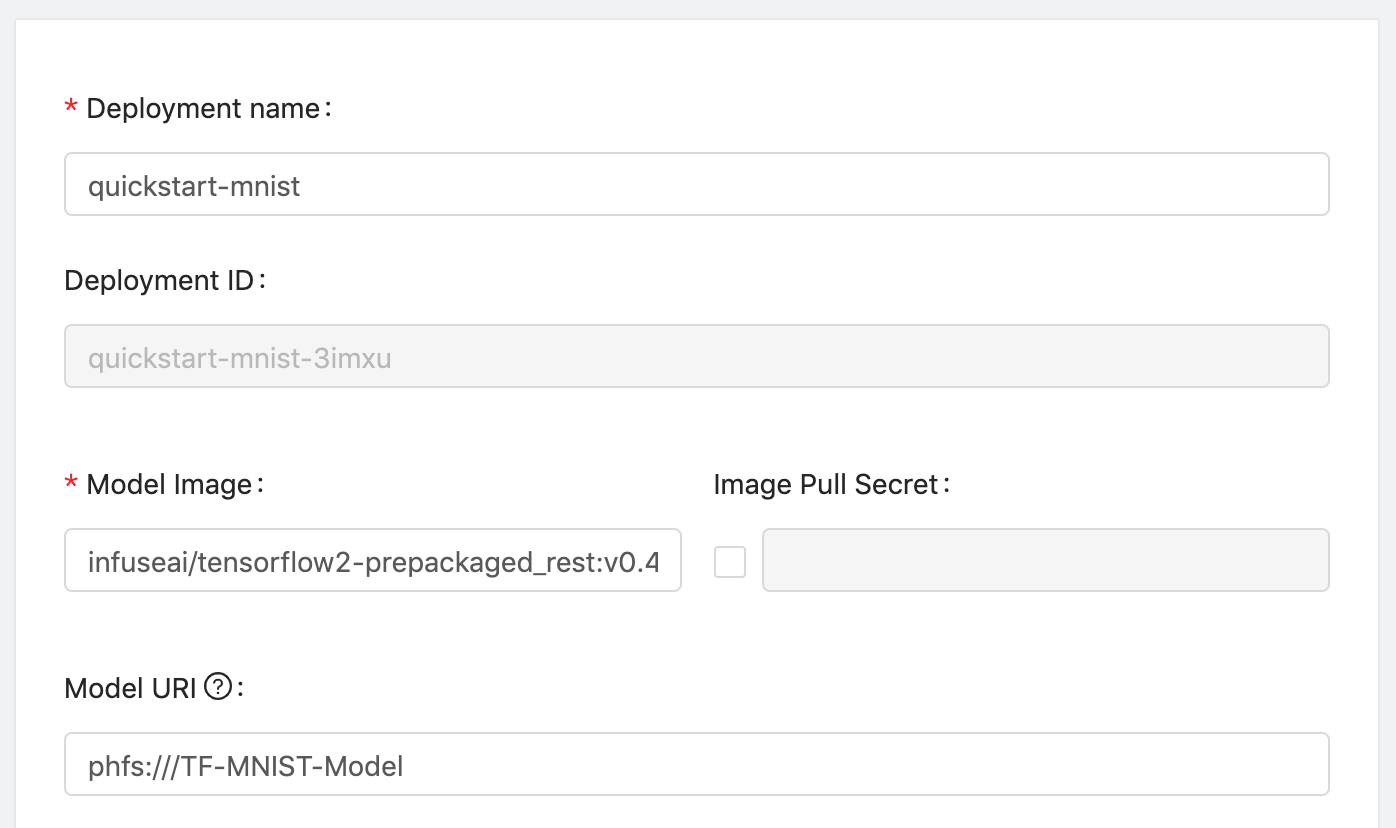
從 container 的視角來看,模型檔會被掛載至 container 的本地檔案統下,如 /mnt/models:
def __init__(self, model_uri=None):
self.model_uri = model_uri
...
因此須於 __init__ function 指定 model_uri 參數並給予 None 作為預設值;表示我們的 Model 有無 model_uri 都可以支援。 當使用者帶入 Model URI 值時,__init__ 就可以從變數 model_uri 取得此值(路徑);我們也可以印出此值來確認載入路徑。
常見作法會利用 load function 來定義模型載入並建立實體物件:
def load(self):
...
當然,如果我們的 load 函式很簡易,我們也可以將 load 一併寫在 __init__;函式分開是一個常見做法。
參照 Model URI 了解更多。